
Learn directly from senior engineers and get daily code reviews, exclusive 1:1 coaching, and live instructor-led sessions every week
Landing your first tech job can seem impossible without a CS degree. From resume critiques to mock interviews and more, I got the support I needed to ensure that becoming a software engineer was not only possible, but inevitable.

Kevin Morehouse
Software Engineer
Qgiv
My manager suggested something similar could be created with a mentor at work, but not a chance. Once you notice the nuance in sequencing, in feedback, even incentives, you realize it's unlike anything else.

Rick Hallett
Software Engineer
Edited
What I appreciate most is being held to a high bar in the assessments. I have to put in my best effort or I'll get called out. This accountability pushes me to be my best and is really hard to recreate on my own.

James Squillante
Senior Software Engineer
Zeal
A fully integrated platform
Everything you need in one seamless platform. Master algorithmic problem-solving, build complex web applications, and supercharge your career with personalized coaching.



Faculty
Learn from engineers that have worked at the best companies and have honed their teaching across thousands of students.
Gordon Zhu
Previously at Google, University of Pennsylvania
Gordon founded Watch and Code in 2014. Previously, he was at Google, where he worked in engineering, product management, and marketing. He studied economics at the University of Pennsylvania.
Lily Gentner
Previously at Uber, Square, Harvard University
Lily joined Watch and Code in 2022 as an instructor. Previously, she worked as a software engineer at Uber and Square. She studied statistics and computer science at Harvard University.
Built for your unique situation
Our services seamlessly scale up and down to help you reach your most audacious goals. From your first role, to senior, and beyond, we provide you with the critical infrastructure for continued growth.
We're a good fit if...
We're a no-brainer if...
We're a bad fit if...
Testimonials
Complete beginners and experienced pros love Watch and Code.
Landing your first tech job can seem impossible without a CS degree. From resume critiques to mock interviews and more, I got the support I needed to ensure that becoming a software engineer was not only possible, but inevitable.
Kevin Morehouse
Software Engineer
Qgiv
My manager suggested something similar could be created with a mentor at work, but not a chance. Once you notice the nuance in sequencing, in feedback, even incentives, you realize it's unlike anything else.
Rick Hallett
Software Engineer
Edited
What I appreciate most is being held to a high bar in the assessments. I have to put in my best effort or I'll get called out. This accountability pushes me to be my best and is really hard to recreate on my own.
James Squillante
Senior Software Engineer
Zeal
Watch and Code outshines my $25,000, 4-year degree. What sets it apart is the personalized attention. No more settling for the bare minimum and apathetic professors. They know exactly how to push me to my limits and get the most out of every opportunity.

Yousuf Idris
Software Engineer
SPRCHRGR
Coming out of a coding bootcamp gave me an impression of coding competence. This is much more than that. I’m improving my thinking and problem solving in a concrete and personalized way - a meta skill that is agnostic of technology.

Ranjit Saimbi
Senior Software Engineer
Hurtigruten Group
Personalized feedback on everything is a game changer. Not only do they spot issues that are easy to miss, but they go deep into the underlying reasoning behind everything.

Janelle de Ment
Software Engineer
Mutiny
If there was a better way, I'd be doing it. While the mastery-based thing sounds all good, I'll be honest, it can be painfully frustrating at times. But, I've progressed more in 12 months here than I did in the last 10 years on my own. This is rewarding beyond words.

Luke Nailer
Communications, Victorian Government (Australia)
Being able to validate business ideas on my own has been really useful. In my latest startup, I was able to build a prototype that we're now testing with real users.

Zack Davies
Former COO
TYB
Gordon and Lily have helped me identify bad habits and misconceptions with their rare ability to empathize with my thought process. This has helped me get better at figuring things out on my own instead of relying on constant Googling and trial-and-error.

Kenny Chow
Software Engineer
Volan Technology
Selective admissions
Be part of a selective community where you'll be surrounded by bright, curious, and hardworking people.
If you're experienced:
If you're a beginner:
Due to the self-paced nature and mastery-based assessments, duration to some goal (e.g. career change, more competitive role) varies wildly. It depends on many factors like your ability, effort, goals, educational background, and the hiring market.
There is absolutely intense sales pressure to market very short, unrealistic timelines accompanied by fudged success rates. Not only is this dishonest, but it's counterproductive because it pushes students to cut corners.
As part of the admissions interview, we're happy to provide an estimate based on your performance and background. For admitted students, we can provide better estimates that incorporate evidence from assessments, live sessions, and interview post-mortems.
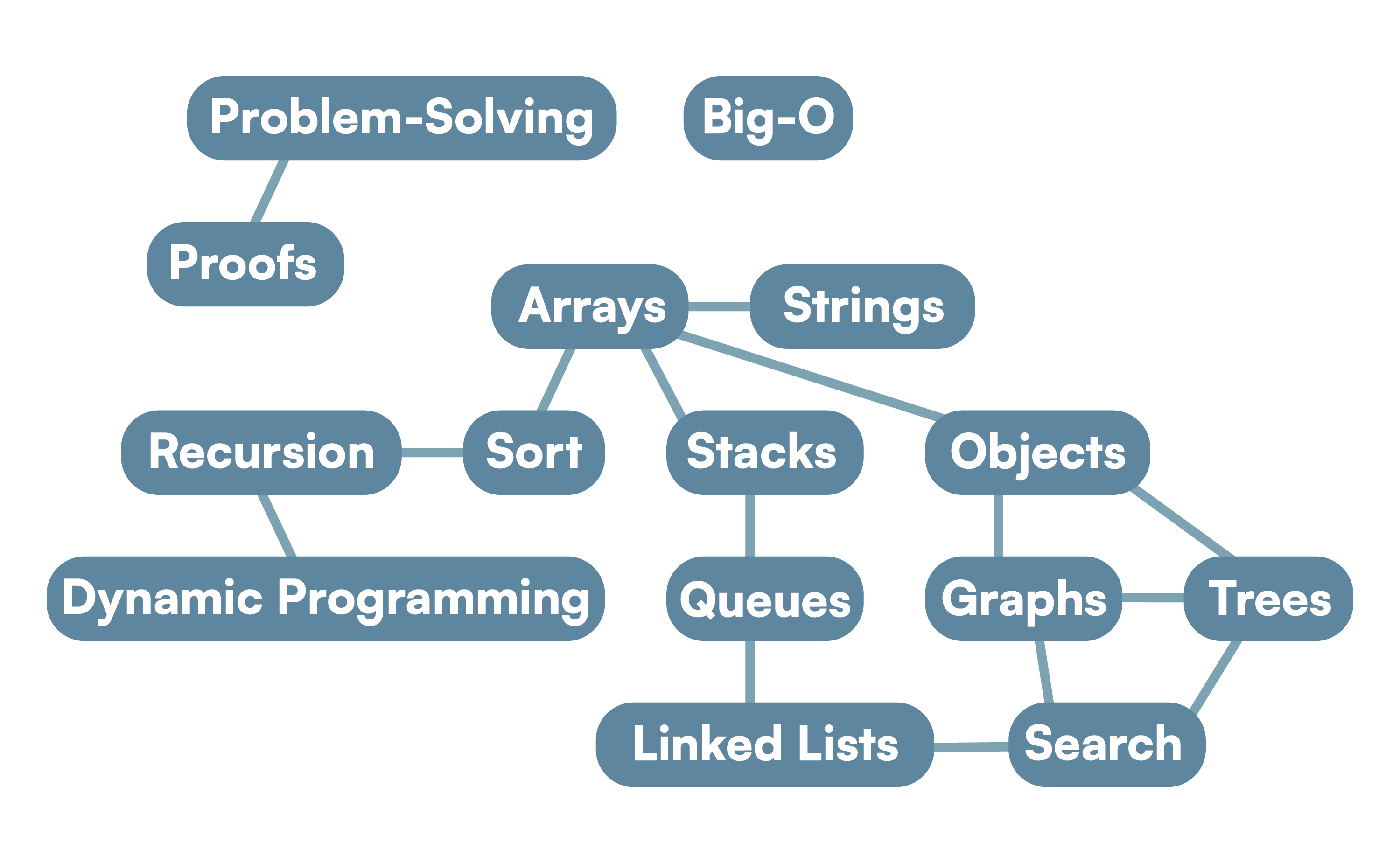
Our Algorithms Intensive uses a language-agnostic subset of JavaScript we call FoundationScript. We do this because we want our students to learn algorithms in a way that is broadly applicable and not language-dependent.
Our Web Development Labs use standard JavaScript. It’s not possible to use FoundationScript here because interacting with third-party code is unavoidable in web development.
Fridays at 8:30-9:30AM Pacific Time. In case that doesn’t work for you, we always record the sessions so that you can watch them later.
As of January 2024, 41% are experienced engineers. The remaining 59% are split between beginners, founders, and hobbyists. This is a testament to how we're able to adapt to the unique needs of each student.
Send us a note at [email protected].
Interested in learning more?
Subscribe to our newsletter to get updates about our latest products, videos, essays, and lessons.